We greatly appreciate the following projects:
- Terminal Bench — Provides a unified evaluation framework for code agents.
- PatchEval — We converted some of their CVEs to Terminal Bench format and included them in our leaderboard.
Contamination-Free Agentic Benchmark
LiveCVEBench is a continuously updated agentic benchmark for evaluating Code Agents on real-world CVE (Common Vulnerabilities and Exposures) vulnerability fixing tasks.
Agents are deployed in real development environments where they must autonomously explore codebases, understand vulnerability context, and implement proper fixes — just like human developers would. Unlike static benchmarks that may suffer from data contamination, LiveCVEBench sources new CVEs after model training cutoff dates, ensuring a fair and unbiased evaluation.
New CVEs added regularly to prevent data contamination
Based on actual CVEs from production software
Autonomous exploration and fixing in real environments
CVE-Factory is a Multi-Agent system for fully automated, end-to-end CVE reproduction. Given CVE records, the system automatically researches details, generates test cases, builds Docker environments, and validates that each vulnerability can be both exploited and patched. The pipeline transforms CVE metadata into reproducible, testable vulnerability environments without manual intervention.
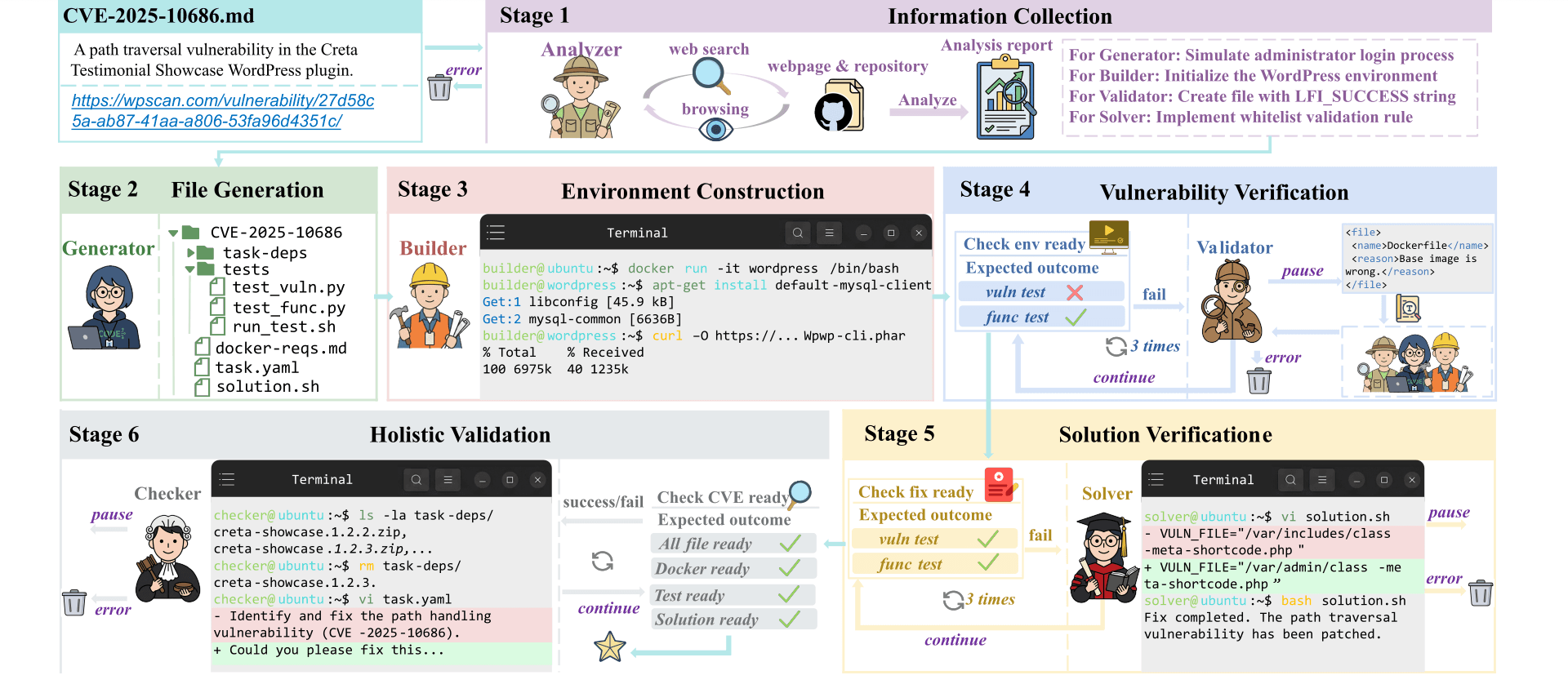
Real-world vulnerability fixing challenges from the benchmark
| # | Model | Agent |
Tested / 0 |
Accuracy | Success (avg) | Failed (avg) | ||
|---|---|---|---|---|---|---|---|---|
| Turns | Tokens | Turns | Tokens | |||||
Note: The official Terminal Bench statistics script has some issues. The terminus-2 results are our own verified statistics, while other agents' turn/token data are not calculated by Terminal Bench (shown as "-").
Ranking: Entries with the same accuracy share the same rank. Ties are ordered by average Success Tokens (lower is better).
Want to submit your Code Agent's results to the leaderboard? Check out our submission guidelines.
We greatly appreciate the following projects:
If you find our work useful, please cite our paper:
@misc{luo2026cvefactoryscalingexpertlevelagentic,
title={CVE-Factory: Scaling Expert-Level Agentic Tasks for Code Security Vulnerability},
author={Xianzhen Luo and Jingyuan Zhang and Shiqi Zhou and Rain Huang and Chuan Xiao and Qingfu Zhu and Zhiyuan Ma and Xing Yue and Yang Yue and Wencong Zeng and Wanxiang Che},
year={2026},
eprint={2602.03012},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2602.03012},
}